欢迎您访问广东某某机械环保科有限公司网站,公司主营某某机械、某某设备、某某模具等产品!
全国咨询热线: 400-123-4567



 新闻资讯
新闻资讯 哈希游戏| 哈希游戏平台| 哈希游戏APP
哈希游戏| 哈希游戏平台| 哈希游戏APP哈希游戏- 哈希游戏平台- 哈希游戏官方网站在淘宝搜索场景下,用户Query与候选商品(Item)之间的相关性判别是非常重要的一环,它筛选出该Query下最相关的商品, 是用户体验的基石。过去几年主搜在相关性场景上已经做了不少工作,并且取得了显著的正向收益,今年,为了进一步解决部分口语化Query承接效果较差的问题,我们又引入了更大参数量(激活3.5B的MoE)的LLM模型,同时扩展了单次打分商品个数,这给我们的系统性能提出了巨大挑战。主要体现在:
相关性模型选用的是激活3.5B的MoE模型,直接发送全部请求给单机推理,响应时间会长达数秒,这对于主搜是绝对不可接受的。为了降低时延,我们进行了横向扩展,通过拆批并行计算加速。假设下游有N个推理节点,单次推理M个(Query, Item)对,理论上,将M个pair拆为n个小批次(nN),每批包含(M/n)个pair并行发送,理想情况下RT可降低至原来的1/n。然而,传统的服务发现与负载均衡组件(如VIPServer)通常基于请求粒度进行随机分发,无法保证瞬间并发子请求的均匀,导致下游部分机器出现排队,拉高了整体RT;
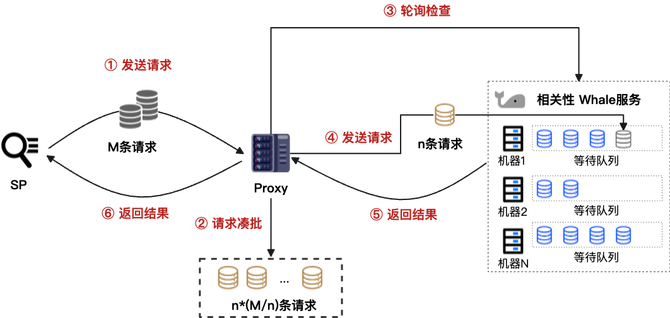
起初,为了快速迭代和验证想法,Proxy 服务采用了 Python 实现。然而,在实际部署上线后,受限于Python在高并发场景下固有的性能瓶颈和GIL 及 GC 机制,经常出现剧烈毛刺,严重影响了服务的稳定性。为了解决这一问题,我们将Proxy 服务迁移至天生支持高并发的 Go 语言重构。迁移完成后,效果立竿见影:服务毛刺大大缓解,在晚高峰时段,P99 延迟从原先的 800ms 大幅下降至 500ms,降幅达 300ms,有力地保障了在线服务的稳定性。
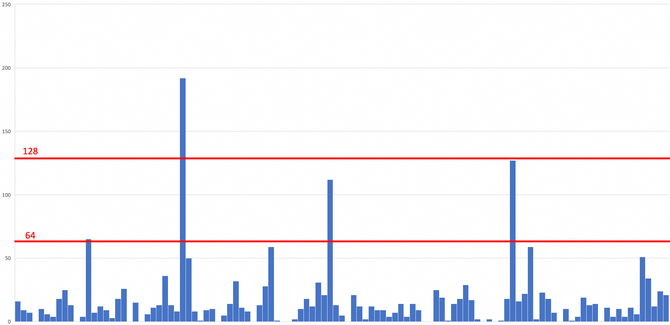
可以看出,绝大多数专家分配到的Token数量都小于64,只有极个别专家的Token数超过128。这种稀疏的负载和底层执行机制产生了冲突,因为我们采用的MoE后端是DeepGemm,其默认的计算粒度blockM是128。实际计算时,为了充分利用Tensor Core进行高效的矩阵运算,DeepGemm会将每一个专家分配的Token数padding到128的整数倍。这种方式在当前场景引入了大量的无效计算,造成了算力浪费。
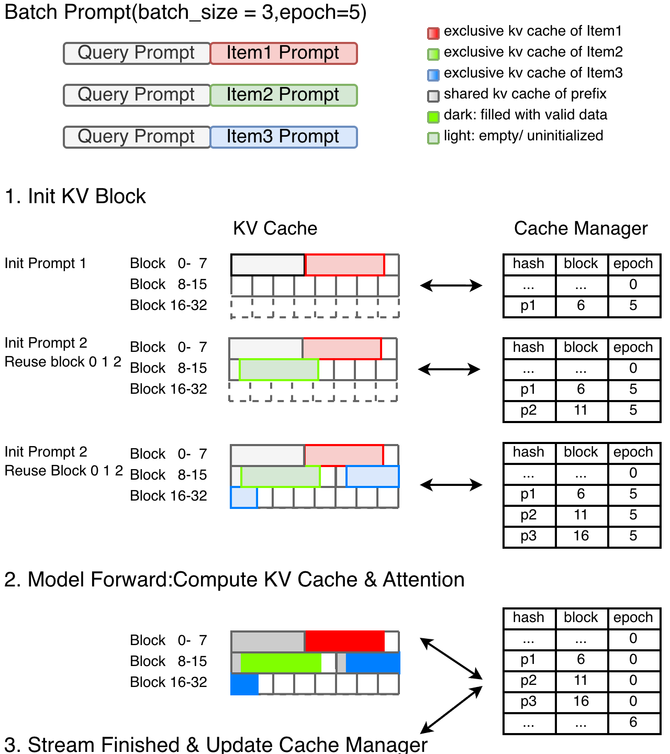
批次内前缀复用还有一个可以改进的优化点:以kv cache page为单位的复用会导致不足一个page的前缀不在复用范围内。例如公共前缀的长度为90,page size为64,那么会有64长度的前缀被复用,而剩下的90-64=26个token则仍然需要被反复计算。我们可以写一个专用的attention来避免重计算这部分,充分利用相同的前缀。我们尝试做了一个demo,结果显示,还有额外的端到端3%-5%的优化潜力。
